Machine Learning Voorspelt Hoogste Risico Grondwaterlocaties voor Verbetering van Waterkwaliteitsmonitoring
Onderzoekers ontwikkelen machine learning-kader voor het voorspellen van schadelijke stoffen in grondwater
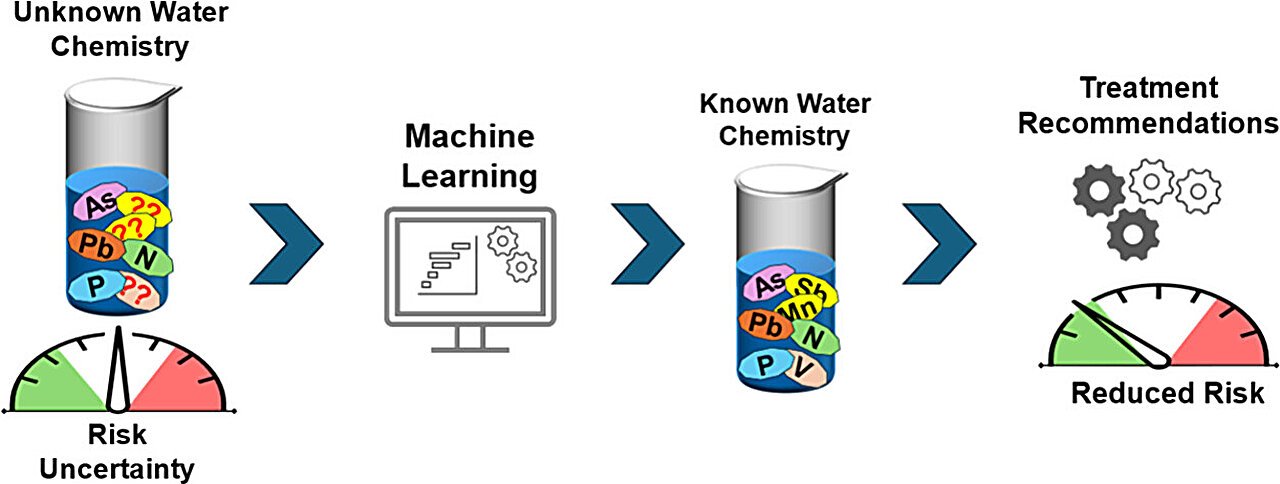
Een interdisciplinair team van onderzoekers heeft een machine learning-kader ontwikkeld dat gebruikmaakt van beperkte waterkwaliteitsmonsters om te voorspellen welke anorganische verontreinigingen waarschijnlijk aanwezig zijn in een grondwatervoorraad. Dit nieuwe hulpmiddel stelt regelgevers en volksgezondheidsautoriteiten in staat om specifieke aquifers te prioriteren voor waterkwaliteitsonderzoek.
Dit proof-of-concept-onderzoek richtte zich op Arizona en North Carolina, maar kan worden toegepast om kritische hiaten in de grondwaterkwaliteit in elke regio te vullen. Het artikel, getiteld “Multiple Data Imputation Methods Advance Risk Analysis and Treatability of Co-occurring Inorganic Chemicals in Groundwater,” is open access gepubliceerd in het tijdschrift Environmental Science & Technology.
Grondwater is een bron van drinkwater voor miljoenen mensen en bevat vaak verontreinigingen die gezondheidsrisico’s met zich meebrengen. Veel regio’s beschikken echter niet over volledige datasets van de grondwaterkwaliteit. “Het monitoren van de waterkwaliteit kost veel tijd en geld, en hoe meer verontreinigingen je test, hoe tijdrovender en duurder het wordt,” zegt Yaroslava Yingling, co-corresponding author van het artikel en Kobe Steel Distinguished Professor in de Materialenwetenschap en Engineering aan de North Carolina State University.
Yingling voegt toe: “Er is interesse in het identificeren van welke grondwatervoorzieningen prioriteit moeten krijgen voor testen, zodat we de beperkte monitoringsmiddelen optimaal kunnen benutten. We weten dat natuurlijk voorkomende verontreinigingen, zoals arseen of lood, vaak samen met andere specifieke elementen optreden door geologische en milieufactoren.”
“Dit stelde een belangrijke datavraag: kunnen we, met beperkte waterkwaliteitsgegevens voor een grondwatervoorziening, de aanwezigheid en concentraties van andere verontreinigingen voorspellen?” zegt Alexey Gulyuk, co-eerste auteur van het artikel en docent in de materialenwetenschap en engineering aan NC State.
Om deze uitdaging aan te pakken, maakten de onderzoekers gebruik van een enorme dataset die meer dan 140 jaar aan waterkwaliteitsmonitoringgegevens voor grondwater in de staten North Carolina en Arizona omvatte. Deze dataset bevatte meer dan 20 miljoen datapunten en dekte meer dan 50 parameters van waterkwaliteit.
“We hebben deze dataset gebruikt om een machine learning-model ’te trainen’ om te voorspellen welke elementen aanwezig zouden zijn op basis van de beschikbare waterkwaliteitsgegevens,” zegt Akhlak Ul Mahmood, co-eerste auteur van het werk en voormalig Ph.D.-student aan NC State. “Met andere woorden, zelfs als we alleen gegevens hebben over een handvol parameters, kan het programma nog steeds voorspellen welke anorganische verontreinigingen waarschijnlijk in het water aanwezig zijn en hoe overvloedig deze verontreinigingen zijn.”
Een belangrijke bevinding van de studie is dat het model suggereert dat verontreinigingen de drinkwaternormen in meer grondwatervoorraden overschrijden dan eerder gedocumenteerd. Terwijl actuele gegevens uit het veld aangaven dat 75%-80% van de bemonsterde locaties binnen veilige grenzen viel, voorspelt het machine learning-kader dat slechts 15% tot 55% van de locaties daadwerkelijk risicoloos kan zijn.
“Als gevolg hiervan hebben we verschillende grondwaterlocaties geïdentificeerd die prioriteit moeten krijgen voor aanvullend onderzoek,” zegt Minhazul Islam, co-eerste auteur van het artikel en Ph.D.-student aan de Arizona State University. “Door potentiële ‘hotspots’ te identificeren, kunnen staatsinstanties en gemeenten middelen strategisch toewijzen aan risicovolle gebieden, wat zorgt voor gerichter monstername en effectieve waterbehandelingsoplossingen.”
“Het is uiterst veelbelovend en we denken dat het goed werkt,” zegt Gulyuk. “De echte test zal echter zijn wanneer we het model in de praktijk gaan gebruiken en zien of de voorspellingsnauwkeurigheid standhoudt.”
In de toekomst zijn de onderzoekers van plan het model te verbeteren door de trainingsgegevens uit te breiden naar diverse regio’s in de VS; nieuwe gegevensbronnen, zoals milieugegevenslagen, te integreren om opkomende verontreinigingen aan te pakken; en real-world tests uit te voeren om robuuste, gerichte maatregelen voor de veiligheid van grondwater wereldwijd te waarborgen.
“We zien enorme mogelijkheden in deze aanpak,” zegt Paul Westerhoff, co-corresponding author en Regents’ Professor aan de School of Sustainable Engineering and the Built Environment aan ASU. “Door de nauwkeurigheid voortdurend te verbeteren en het bereik uit te breiden, leggen we de basis voor proactieve waterveiligheidsmaatregelen over de hele wereld.”
“Dit model biedt ook een veelbelovend hulpmiddel voor het volgen van fosforniveaus in grondwater, waardoor we potentiële verontreinigingsrisico’s efficiënter kunnen identificeren en aanpakken,” zegt Jacob Jones, directeur van het Science and Technologies for Phosphorus Sustainability (STEPS) Center aan NC State.
“Als we vooruitkijken, kan het uitbreiden van dit model om bredere fosforduurzaamheid te ondersteunen een significante impact hebben, waardoor we dit essentiële voedingsmiddel in verschillende ecosystemen en landbouwsystemen kunnen beheren en uiteindelijk duurzamere praktijken bevorderen.”